 There is nothing like unclear or poorly described requirements – or more generally speaking wrong input – to put undue pressure on the output of a development team. Agile processes often result in amazingly productive software machines, but bad input is like throwing sand in that machine.
There is nothing like unclear or poorly described requirements – or more generally speaking wrong input – to put undue pressure on the output of a development team. Agile processes often result in amazingly productive software machines, but bad input is like throwing sand in that machine.
Most software developers can relate to the days they are in and out of meetings without even touching their keyboard. For me, the worst meetings are those where every hypothetical corner case gets discussed, and everybody is surprised why some item is listed that high on the backlog. If this feels familiar you need to start thinking about the quality of input to your team.
Garbage in, garbage out. This decades-old statement still remains relevant in today’s agile way of working. After too many hours of frustration a couple of colleagues and myself decided to address it ourselves. Being a developer, there are few things I like better than solving problems. So let’s take a look at four problems especially common when using digital backlog tracking that I would like to see solved.
Bumping low priority / poorly described (garbage) stories In practice the bottom items of the backlog are usually either insufficiently defined or over-defined and discussed over and over again. At some point someone will bump the priority and we have garbage on the top of the backlog. Next thing, we are discussing garbage in a refinement meeting.
A backlog of over-aged stories Some stories never reach the sprint. You will probably also have a couple of stories that are always excluded from sprints. The thing I like about post-it backlogs is that they eventually fall of. During refinement meetings people tend to disagree on points, depth, breadth, and in a general sense. These are typically the stories about which architecturally-inclined colleagues start shouting that ‘this will break compatibility’ or ‘this will mean a complete overhaul’ and your product owner will shout back: ‘How can that be, it contains almost no functionality’. Ultimately discussions are settled because the story is ‘ill defined’. But how many of these stories are on your backlog?
Mislabeled or ‘upgraded’ stories Bugs are dressed up as user stories to make it look like the team is delivering functionality instead of fixing technical debt. The incorrect labeling of stories can often lead to ill-defined backlog items.
Although all major issue-tracking tools try to provide structure they lack the proper heuristics that really help you to keep your input of a sufficiently high quality. Hopefully some fields can be configured to be mandatory for certain issue types, but let’s face it: people will start adding content in the form of stuffing, when you cannot save an issue without completing the form. Improper information dilutes the story, or is a distraction at the very least.
Duplicates or cousins Didn’t we go over this already? Something, you often hear, or at least think for yourself. In an agile environment. Lots of people still use issue trackers for requirements tracking. Today’s tooling makes it easy to just say: ‘I’ll just make a story for it. In the end you will end up with an enormous list of issues. It can be worse - you could inherit a backlog from your predecessor. The flat list kind of backlogs make it very difficult to retain a feeling of correctness about stories. Sometimes there will be duplicates, where the stories only differ somewhat in detail. Which one is then more accurate? On a physical board you at least have some limitation in terms of physical space. We often resort to labeling to scope down a story, but guess what: stories change just like your software does. Are labels realy good enough to group stories and to reduce the cognitive load of a long list of things? As a developer I just want my stories to be correct and without duplicates, but maybe more importantly, I want to be able to see the extent of grouping of functionality. When discussing architecture it is always good to see a bigger picture.
As a software engineer I feel that all these opportunities for ‘garbage in’ take away the fun in my job. Meetings become needlessly frustrating and time-consuming. I think that a lot of these problems can be addressed by software, but paradoxically I also think software IS the actual cause of some of these problem. Doing physical issue tracking has its own downside, however modern digital issue trackers have definitely shaped the contents of this blog.
For the last year, we have been working on and off on our backlog validation software called Gareth. For developers, it is normal to have your code and software artifacts tested continuously. And we have developed fancy dashboards and monitoring systems over time. For us, this was an inspiration to start continuous backlog validation. We have been iteratively developing and testing with it on ten backlogs the last three months and are happy with the results. Backlogs are scanned and tested daily and results are graphed.
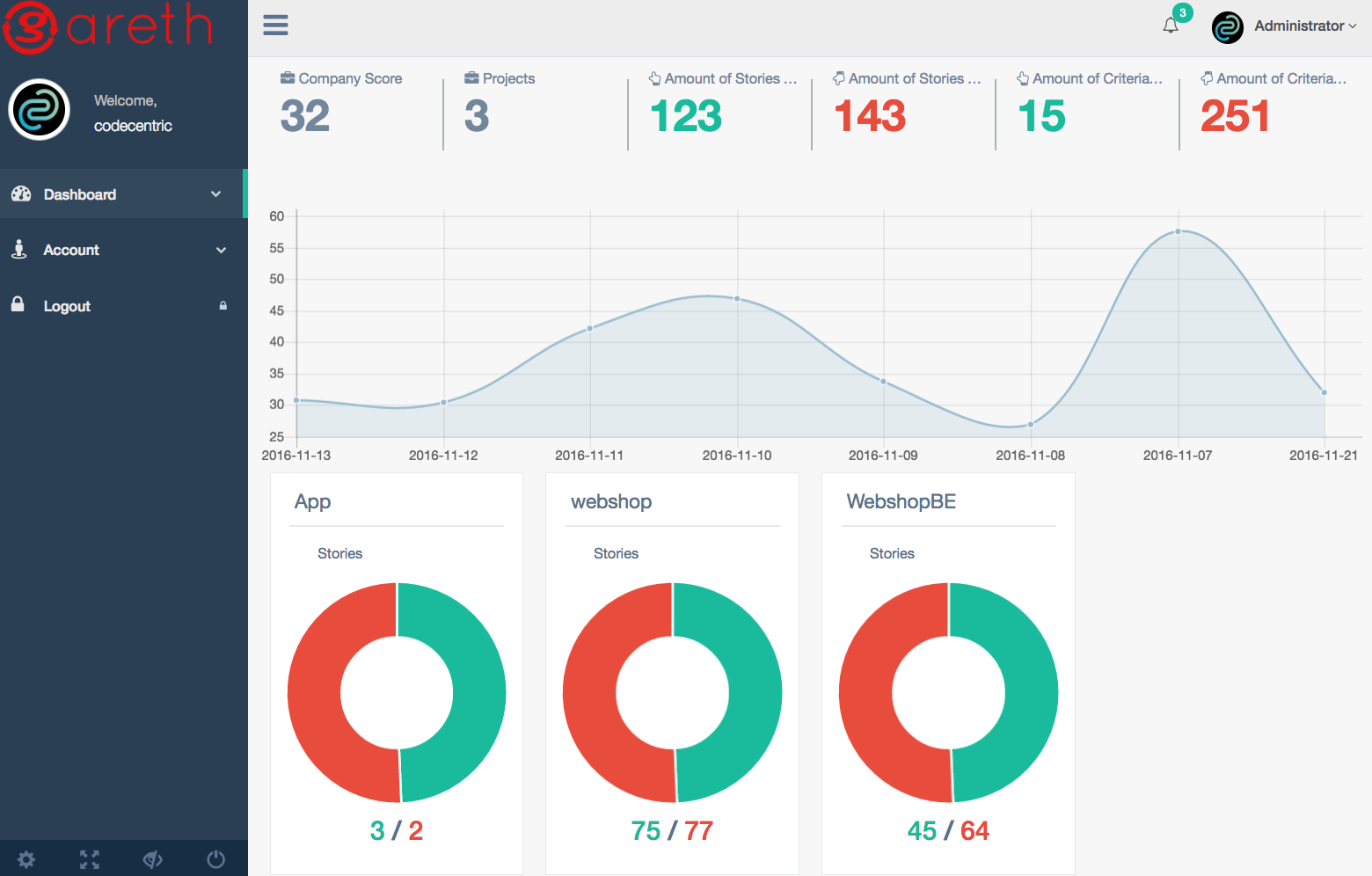
And just like we are proud of a +90% code coverage, product owners are proud of a +90 score on their backlog and will check and correct their backlog on a daily basis. We even included it in our Jenkins monitoring dashboard so everyone can see the backlog ‘failing’ or ‘passing’ the threshold.
Read our blogs for more information on this exciting topic!